本文首发于公众号“土猛的员外”。
在大部分企业和事业单位,非结构化数据占比远大于结构化数据,挖掘非结构化数据的价值,为人们所用,任重道远。
连接的价值

王坚博士的《在线》是一本相对有争议的书,当年出版不久,我记得身边的朋友里就有人踩有人捧。虽然他当时讲的更多是基于云计算和大数据的一些未来发展看法,但是其中有一个重要观点,我觉得在AI时代依然适用,那就是“连接”。连接讲的是数据与互联网的连接,是数据与各类业务系统的连接,只有发生了连接,数据的价值才会像石油遇见内燃机,交流电遇见电动机一痒,价值成倍上升。没有连接的数据就只能变成“沉默数据”,在掸去尘灰再次被人发现之前,这些资料文件毫无价值。
这里讲的更多还是结构化数据,那么数量更加庞大的非结构化数据呢?
从我二十年前开始接触计算机开始,数据更多指的就是结构化数据,比如存在关系型数据库里面的有严格schema的数据,或者存在非关系型数据库里面的带有properties(属性)的JSON格式数据,甚至我们在之前基于NLP的AI智能客服里的corpus(语料库),那也是带有结构关系的QA问答对,需要人工进行抽取再填入。但是这里的问题是,我们可以采取的数据收集方式除了基于系统定义的方式在运行中产生之外,就是只有通过人工进行清洗和导入(ETL)的。而对于一个企业或者事业单位来说,非结构化的数据才是更大占比的存在,比如合同文本、会议纪要、新闻稿、采购单、发票、项目群里的交流记录、电子邮件、财务报表、日报周报、工作计划,还有大量的PPT、Excel和Word/Markdown格式的各类文档等等。我去年从老东家离职的时候,在交还的Macbook Pro上留下了超过100G的这类型文件。

如果企业可以将这些非结构化文件有效利用,结果会如何?
这个答案我们会在本文后面的内容来回答,现在先让我介绍一下本系列的文章结构。
我将开启一个新的系列文章《挖掘非结构化数据的价值》,用5篇文章来详细描述一下如何通过大语言模型(LLM)、检索增强生成(RAG)和各类代理(Agent)等技术实现非结构化数据价值的发掘。这些文章的大致内容(后续可能会有调整)包括:
挖掘非结构化数据的价值(1)—通过RAG实现与文件对话
挖掘非结构化数据的价值(2)—通过DSPy实现文件与应用的连接
挖掘非结构化数据的价值(3)—如何使用Fusion实现解决多文档检索问题
挖掘非结构化数据的价值(4)—如何用AI检测合同与合规问题
挖掘非结构化数据的价值(5)—如何用多项AI技术组合实现项目预审批辅助
与非结构化文件建立对话
今天我们先来讲讲如何利用LLM+RAG与文件对话,让文件自己告诉我们想要的答案。
在LLM和RAG被逐渐被应用之前,我们对文件内容其实也是有一些管理方法的,比如我敬爱的泥叔(前同事),基本上就是everything的拥趸。我们简单说一下之前的一些方法吧:
- 文件全文检索:代表工具是Everything和Raycast等,虽然Everything也可以勉强使用
content:来检索文件内容,但是他们赖以成名的还是对文件名和文件夹名的检索; - 传统NLP技术:NLP相对来说更接近于“连接”非结构化文件,但是在很多时候,我们需要有大量人工投入去解决语料库维护(阅读文件、抽取内容、制作QA对等),成本高启,推广难度非常大。而且意图理解能力还是真的比较弱,如果不堆叠很多相似问法,就会变成“白痴”;
除了这些显而易见的问题,其实这些方法还有两个非常严重问题:
- 很难理解大段文字的问题输入,也就意味着完全没有和非结构化文件对话的感觉,对于大部分用户来说易用性很差;
- 无法跨多文件进行内容挖掘,也不会对结果进行最终的汇总加工,比如去除重复内容,将多个召回结果按一定的规律进行排序等等。
所以要实现与非结构化文件对话,目前最合理、最经济的就是使用最新的RAG技术,当然肯定是依赖于大语言模型(LLM)作为底座的。
关于RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是为大语言模型 (LLMs) 提供了从数据源(一般可以认为是各类已经获得的文件资源)检索的信息,以此为基础生成回答。简而言之,RAG 结合了搜索技术和大语言模型的提示(Prompt)功能,即模型根据搜索算法找到的信息作为上下文来回答查询问题。无论是查询还是检索的上下文,都会被整合到发给大语言模型的提示中,然后让大语言模型根据召回的事实内容进行润色输出。
在2023 年,大语言模型逐渐火热之后,基于 RAG 架构的大语言模型系统成为最受欢迎的技术之一。许多产品几乎全依赖 RAG 架构,这包括结合网络搜索引擎和大语言模型的问答服务,以及数以百计的数据交互应用程序。
RAG流程介绍

如上图所示,RAG的大致流程包括:
- 首先,会从用户给定的文档、图片、表格和外部URL等资源中提取内容;
- 然后通过chunking(可以认为是将连续的文本分成一个个小块)进行合理切割,再使用embedding过程变成向量数据存入向量数据库或elasticsearch等载体中。另外就是结合这些非结构化文件所附带的元数据(时间、文件名、作者、副标题、文件类型等)对进行索引(高级索引可以是树结构、图结构等)创建;
- 接下来就是用户的使用过程了,当RAG接受到用户的提问内容,会先将内容通过embedding转化为向量数据,然后和在前面建立的索引中进行相似度匹配,比如从百万的chunks中找出匹配度较高的100个。然后再将这100个chunk进行更耗时也更精准的重排序(使用交叉熵校验的Rerank算法),将最相关的top3结果找到;
- 最后RAG会将用户的问题、经过技术处理的top3的chunks,还有prompt,一起送入大语言模型,让它生成最终的答案。
RAG的优势
RAG结合大语言模型使用,可以有效解决大语言模型本身存在的三个主要问题:
- 私有数据和时效性:大语言模型可以通过预训练和后期微调(Fine-tuning)将大家的私有数据(如您公司的业务文件等数据)压缩,提供给用户使用。但问题是哪怕是微调也是非常耗费资金的,加上微调本身存在一些技术要求,对于非技术专业的用户来说,要想“立即马上”与自己最新鲜的私有数据进行对话还是存在很大难度的。而RAG则是采用“外脑”的方式处理这个问题,只要用户将最新的资料进行上传,即可与这些文件进行对话,让他们告诉你想要的答案,将知识时效性快速提升;
- 幻觉问题:当LLMs对于用户行业知识匮乏的时候,比如你问GPT本月公司的各个会议有没有提到“人员优化”的问题,对于这些问题,GPT可能也会出现常见的幻觉问题,一本正经的胡说八道。使用RAG可以基于给定内容进行检索,降低最终输出的幻觉。类似我们TorchV Bot就提供系统级的参数控制,甚至可以设置在检索召回内容质量不高的情况下,禁止LLMs介入,而是直接回复“不知道”;
- 数据安全问题:对于数据安全要求极高的企业用户,如果不想使用在线大语言模型(如ChatGPT、通义千问、文心一言等),那么可以采用完全本地化部署。采用RAG可极大降低LLMs要求,配合百亿级别参数的可本地部署大模型即可提供绝大多数AI服务,还让企业数据保不出内网。另外还有一个角度就是访问权限控制,我们肯定不希望刚进来的实习生也能通过对话知道公司还未发布的财务数据。这些都是RAG作为LLM的外脑可以做到的事情。
好了,介绍了连接的价值,以及如何与非结构化数据建立对话,最后我们来看看建立这种对话之后的好处。
建立对话的价值
常见价值
先讲讲我们在实际业务场景中一些业务能力提升。
对客服务
一般对外服务型的企业,每天都会面临大量的客户咨询,比如客户在使用咱们提供的系统时,会碰到各种各样的问题,这里面最常见的就是客户不了解使用方式引起的咨询(我们不能完全期望客户会去翻看几万字的使用手册或者更详细的“help”文档)。
如果你自己当过一段时间的坐班客服,就会发现90%以上的问题其实都是“老生常谈”的问题。那么,这时候如果咱们可以将几万字的使用手册、一堆帮助中心的文件与对客服务系统建立连接,不仅可以将这些非结构化知识的价值激活,还可以极大提升对客服务的能力。
目前在RAG产品上已经非常成熟,我们也有新能源汽车、政务办事、软件售后和旅游服务等行业的客户正在使用TorchV Bot与自身的各类文档形成连接,构建自己强大的对客服务能力。
生产辅助
在某些知识密集型较高工业生产型企业,拥有大量行业标准,细到更换某个零件需要遵守的11个步骤都被明确写明。类似这样的行业标准(SOP)文件可能多达几百份,平均每份又多达上百页。在进行日常生产或维修的时候,对于很多从业人员都是一种挑战,要么每次翻阅大量标准文件(耗费大量时间),要么凭直觉或经验(带来错误率)。
我们的一位意向客户采用我们的TorchV Bot(基于RAG和LLM)之后,将这些SOP文件全部喂给Bot,然后直接问:“我现在要更换XX机器上的XXX号零件,需要怎么操作?”,Bot只需几秒就会告诉你11个标准流程,而且附带原文的预览链接。省去了自己翻阅庞杂文件的时间,也减少了生产和维修中的“拍脑袋”错误。
与非结构化数据对话的底层需求
下面我再举一个案例,说明人类需要与大量非结构化数据建立对话的底层原因。
国内存在大量的项目型公司,他们的主要业务就是涉及智慧城市、智慧医疗、智慧交通和智慧旅游等类型的项目,这些单体项目往往项目金额巨大、周期跨度长(通常1-3年)、参与人员庞杂。我上文提到的超过100GB的交接文件中有一半属于这方面的资料,包括从商机、需求调研开始的各类资料,到可研与立项的各种规范文件,再到整个项目的设计、研发与实施过程的管理文件。
这个过程中,如果出现核心人员变动(100%会发生),如人员离职、新人加入、人员调岗,甚至主要领导更换,都会造成项目过程管理的混乱。比如新负责人会问:“这个规格从立项文件里面规定的7%调整到现在的9.2%,是谁决定的?什么原因?”,如果项目组人员变动大,多数情况下可能就问不出答案,这时候项目组人员也许只能在成千上万的项目资料中去找答案。如果此时我们可以激活文件的价值,让我们可以与它们建立对话,那项目管理的效率和结果肯定会大大提升。
类似于上文提到过的项目管理过程,如果使用TorchV Bot进行管理,项目人员可以向Bot提问:“这个规格从立项文件里面规定的7%调整到现在的9.2%是谁决定的?什么原因?”。Bot的回答会先把结果告知您,如“立项文件中XXX规格从7%调整为9.2%是由沈总在2021年6月17日的项目会议中提出的,主要原因是为了给后续升级提供性能的冗余。具体内容可参见?《项目会议纪要-2021035.pdf》”,然后给出文件的引用,用户可点击打开文件查看原文。
在历史中有很多工具被发明出来改善人类的能力,比如汽车可以改善人的行动能力,眼镜可以改善人的视力,助听器可以改善人的听力,而类似于TorchV Bot这样的工具,与庞大却零散的非结构化文件进行连接,是可以帮助人改善记忆的。人类一直渴望借助各类工具提升自己,我认为这就是我们渴望建立与这些文件建立对话的底层需求。
进一步挖掘价值
其他的一些应用我们会在后面的文章中继续介绍,比如:
报销优化
在上班那些年,每次临近季度、半年度和年度节点的时候,总会看到大多数同事会花个几天时间在一张张梳理发票,填各种报销单,尤其是很多销售人员都会特意回总部进行填报。这种工作费时费力,而且对于公司来说时间成本损失是非常大的。此类工作如果可以让机器快速识别各类发票、单据,那么就可以与出差申请、费用申请流程相结合,快速完成报销和审批的自动化。不仅节省销售人员报销时间(几十个销售人员,一个季度就可以浪费掉近百个“人·天”),也可以为财务审批人员减轻工作量。
这部分会在第四篇文章里面提及。
审批优化
审批自动化在企事业单位的应用场景很多,最简单的包括合同预评审。法务工作中很多时间是浪费在一些初级问题的发现和纠正过程中的,比如合同的格式问题、必填项缺失、数额无法对齐、错别字、付款条件不清晰等。这些问题均可以使用系统进行预审,让发起人通过与机器交互,改进此类问题之后,再交由法务人员处理。得到的好处是可以让法务人员更加集中精力处理核心问题,甚至减少法务人员的HeadCount。
还有就是项目审批的过程,各类审批都有相应的审批制度,然后审批人员对照制度来对项目审批提交的各类文件进行审阅,过程漫长繁琐。如何通过大语言模型、RAG,以及Agent,帮助审批人员完成耗时最长的前40%工作?我们会在第五篇文章提到。
其他
以上还只是我们遇到的客户场景中很小的一部分,包括金额行业根据大量资料自动生成目标公司的综合分析报表,包括快速定位问题帮助员工正确操作这种业务的指南助手等等,都是我们将非结构化文档与业务系统连接之后可以挖掘出来的价值。
而相对于结构化数据(抛开那些日志数据,其实它们也属于非结构化数据),非结构化数据在数量上远远多于结构化数据,所以让非结构化数据“连接”到业务系统中,将会为企事业单位挖掘出巨大的价值。
结论
本文在整个系列文章中属于开篇入门文章,提到的技术内容很少,更多对AI如何提升业务能力的一些思考,但观点更多来自于自身感受,以及在帮助客户过程中发现的一些感悟,肯定存在片面的观点,所以不足之处还请大家指正。
整个信息行业发展了几十年,对于数据价值的挖掘总体上还存在对结构化数据的应用。随着AI技术的发展,现在已经具备对数量更加庞大的非结构化数据进行应用的能力,对于TorchV来说,挖掘文本、图像、视频等非结构化数据的价值,值得我们好好去深耕!
附录
当然,最后还是要推荐一下我们的产品—TorchV AI。
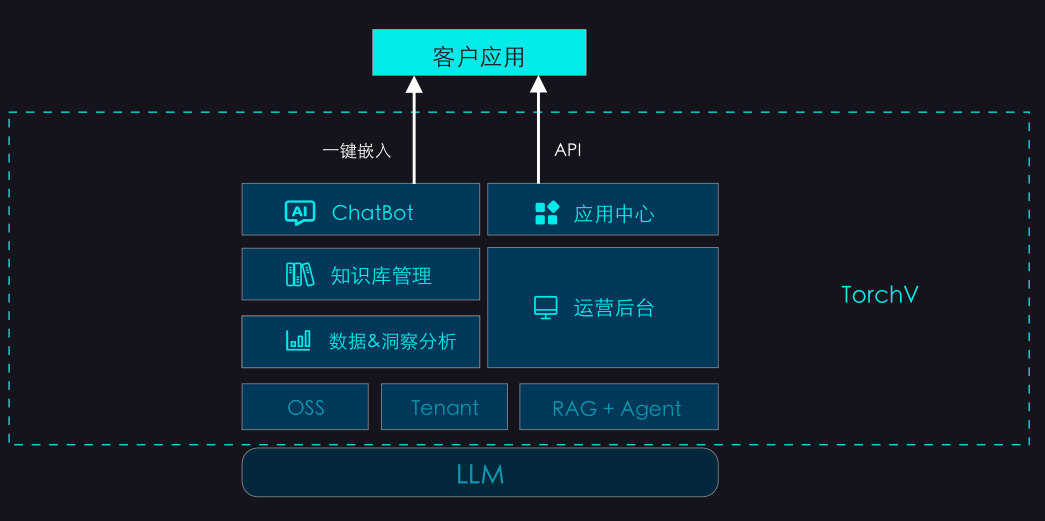
目前已经支持API开放,可以将能接接入第三方应用
TorchV AI就是这么一款可以让您和那些处于沉默状态的文件连接的产品,基于国产大语言模型和RAG技术。目前我们已经开放试用,SaaS形式,如果您是企业用户,可以联系我(wx:lxdhdgss)获得试用账号,登录就可以直接试用。
欢迎您开启与非结构化数据对话之旅!